JUNGLE 240325 (W01)
KRAFTON JUNGLE Week 01
1. Keywords
힙 정렬 (Heap Sort)
- 힙의 특성을 이용하여 정렬하는 알고리즘
- 힙(heap): 부모의 값이 자식의 값보다 항상 크다는 조건을 만족하는 완전 이진 트리
✔ Heapify : 주어진 배열을 힙으로 변환하는 함수
def Heapify(arr, index, heap_size):
largest = index # 부모 노드
left = 2 * index + 1 # 왼쪽 자식 노드
right = 2 * index + 2 # 오른쪽 자식 노드
# 부분 트리를 힙으로 만들기
if left < heap_size and arr[left] > arr[largest]:
largest = left
if right < heap_size and arr[right] > arr[largest]:
largest = right
if largest != index:
arr[index], arr[largest] = arr[largest], arr[index]
Heapify(arr, largest, heap_size) # 하위 서브트리를 힙으로 만듦 (재귀 호출)
✔ HeapSort : 힙에서 최댓값을 반복적으로 추출하여 정렬하는 함수
def HeapSort(arr):
n = len(arr)
# 주어진 배열을 힙으로 만듦
for i in range(n//2 - 1, -1, -1):
Heapify(arr, i, n)
# 최댓값을 추출하여 배열을 정렬
for i in range(n - 1, 0, -1):
arr[0], arr[i] = arr[i], arr[0] # 최댓값을 배열의 끝으로 이동
Heapify(arr, 0, i) # 힙 속성을 유지하기 위해 Heapify 호출
return arr
자료 구조 (Data Structure)
추가 설명은 여기로.. Click!!
스택 (Stack)
- LIFO (Last In First Out): 나중에 들어온 것이 먼저 나감
Push: 스택에 데이터를 넣는 작업 /Pop: 스택에서 데이터를 꺼내는 작업stk: 스택 배열 /capacity: 스택 크기 /ptr: 스택 포인터
class Stack:
class Empty(Exception):
pass
class Full(Exception):
pass
Empty: 스택이 비어 있으면 내보내는 예외 처리Full: 스택이 가득 차 있으면 내보내는 예외 처리
def __init__(self, capacity: int = 256) -> None:
self.stk = [None] * capacity
self.capacity = capacity
self.ptr = 0
def __len__(self) -> int:
return self.ptr
__init__(): 스택 배열을 생성하는 등의 준비 작업 수행- 스택의 크기를 나타내는 필드인
capacity로 복사하여, - 모든 원소가 None인 리스트형
stk생성, - 이 때 스택이 비어있으므로 스택 포인터의 값인
ptr의 값은 0
- 스택의 크기를 나타내는 필드인
__len__(): 스택에 쌓여 있는 데이터 개수 반환
def is_empty(self) -> bool:
return self.ptr <= 0
def is_full(self) -> bool:
return self.ptr >= self.capacity
is_empty(): 스택이 비어 있는지를 체크하는 함수is_full(): 스택이 가득 차 있는지 체크하는 함수
def push(self, value: Any) -> None:
if self.is_full():
raise Stack.Full
self.stk[self.ptr] = value
self.ptr += 1
def pop(self) -> Any:
if self.is_empty():
raise Stack.Empty
self.ptr -= 1
return self.stk[self.ptr]
def peek(self) -> Any:
if self.is_empty():
raise Stack.Empty
return self.stk[self.ptr - 1]
push(): 스택에 데이터를 추가하는 함수- 전달받은
value를 배열 원소stk[ptr]에 저장하고 스택 포인터ptr을 1 증가
- 전달받은
pop(): 데이터를 꺼내서 반환하는 함수- 스택 포인터
ptr의 값을 1 감소시키고stk[ptr]에 저장된 값을 반환
- 스택 포인터
peek(): 스택의 꼭대기 데이터를 들여다보는 함수- 꼭대기 원소
stk[ptr-1]의 값을 반환, 스택 포인터는 변화 X
- 꼭대기 원소
def clear(self) -> None:
self.ptr = 0
def find(self, value: Any) -> Any:
for i in range(self.ptr - 1, -1, -1):
if self.stk[i] == value:
return i
return -1
def count(self, value: Any) -> int:
c = 0
for i in range(self.ptr):
if self.stk[i] == value:
c += 1
return c
clear(): 스택의 모든 데이터를 삭제하는 함수- 스택 포인터
ptr의 값을 0으로 변경
- 스택 포인터
find(): 데이터를 검색하는 함수- 스택 본체의 배열
stk안에value와 값이 같은 데이터가 포함되어 있는지 확인하고, - 포함되어 있다면 배열의 어디에 들어 있는지를 검색 (선형 검색)
- 스택 본체의 배열
count(): 스택에 쌓여 있는 데이터의 개수를 반환하는 함수
큐 (Queue)
- FIFO (First In First Out): 먼저 들어온 것이 먼저 나감
Enqueue: 큐에 데이터를 추가하는 작업 /Dequeue: 큐에서 데이터를 꺼내는 작업
class Queue:
class Empty(Exception):
pass
class Full(Exception):
pass
Empty: 비어 있는 큐에 함수를 호출할 때 내보내는 예외 처리Full: 가득 차 있는 큐에 함수를 호출할 때 내보내는 예외 처리
def __init__(self, capacity: int) -> None:
self.no = 0
self.front = 0
self.rear = 0
self.capacity = capacity
self.queue = [None] * capacity
def __len__(self) -> int:
return self.no
__init__(): 큐 배열을 생성하는 등의 준비 작업을 하며 5개의 변수에 값을 설정queue: 큐의 배열로서 밀어 넣는 데이터를 저장하는list형 배열capacity: 큐의 최대 크기를 나타내는int형 정수front,rear: 맨 앞의 원소, 맨 끝의 원소를 나타내는 인덱스no: 큐에 쌓여 있는 데이터 개수를 나타내는int형 정수
__len__(): 큐에 추가한 데이터 개수를 반환하는 함수
def is_empty(self) -> bool:
return self.no <= 0
def is_full(self) -> bool:
return self.no >= self.capacity
is_empty(): 큐가 비어 있는지를 판단하는 함수is_full(): 큐가 가득 차 있는지를 판단하는 함수
def enqueue(self, x: Any) -> None:
if self.is_full():
raise Queue.Full
self.queue[self.rear] = x
self.rear += 1
self.no += 1
if self.rear == self.capacity:
self.rear = 0
def dequeue(self) -> Any:
if self.is_empty():
raise Queue.Empty
x = self.queue[self.front]
self.front += 1
self.no -= 1
if self.front == self.capacity:
self.front = 0
return x
enque(): 큐에 데이터를 넣는 함수deque(): 큐에서 데이터를 꺼내는 함수
def peek(self) -> Any:
if self.is_empty():
raise Queue.Empty
return self.queue[self.front]
def find(self, value: Any) -> Any:
for i in range(self.no):
idx = (i + self.front) % self.capacity
if self.queue[idx] == value:
return idx
return -1
def count(self, value: Any) -> int:
c = 0
for i in range(self.no):
idx = (i + self.front) % self.capacity
if self.queue[idx] == value:
c += 1
return c
peek(): 맨 앞 데이터를 들여다보는 함수find(): 큐의 배열에서value와 같은 데이터가 포함되어 있는 위치를 알아내는 함수count(): 큐에 있는 데이터의 개수를 반환하는 함수
연결 리스트 (Linked List)
- 노드마다 뒤쪽 노드를 가리키는 포인터가 포함되도록 구현
data: 데이터에 대한 참조 /next: 뒤쪽 노드에 대한 참조
class Node:
def __init__(self, data: Any = None, next: Node = None):
self.data = data
self.next = next
Node클래스data: 데이터에 대한 참조 (임의의 형)next: 뒤쪽 노드에 대한 참조 (Node 형)
class LinkedList:
def __init__(self) -> None:
self.no = 0
self.head = None
self.current = None
def __len__(self) -> int:
return self.no
__init__(): 연결 리스트를 초기화하는 함수no: 리스트에 등록되어 있는 노드의 개수head: 머리 노드에 대한 참조current: 현재 주목하고 있는 노드에 대한 참조
__len__(): 노드 개수를 반환하는 함수
def search(self, data: Any) -> int:
cnt = 0
ptr = self.head
while ptr is not None:
if ptr.data == data:
self.current = ptr
return cnt
cnt += 1
ptr = ptr.next
return -1
def __contains__(self, data: Any) -> bool:
return self.search(data) >= 0
search(): 인수로 주어진data와 값이 같은 노드를 검색하는 함수- 종료 조건 1: 검색 조건을 만족하는 노드를 발견하지 못하고 꼬리 노드까지 왔을 경우
- 종료 조건 2: 검색 조건을 만족하는 노드를 발견한 경우
__contains__(): 데이터가 포함되어 있는지 판단하는 함수
def add_first(self, data: Any) -> None:
ptr = self.head
self.head = self.current = Node(data, ptr)
self.no += 1
def add_last(self, data: Any):
if self.head is None:
self.add_first(data)
else:
ptr = self.head
while ptr.next is not None:
ptr = ptr.next
ptr.next = self.current = Node(data, None)
self.no += 1
add_first(): 리스트의 맨 앞에 노드를 삽입하는 함수add_last(): 리스트의 맨 끝에 노드를 삽입하는 함수- 리스트가 비어 있을 때와 비어있지 않을 때를 나누어서 처리
def remove_first(self) -> None:
if self.head is not None:
self.head = self.current = self.head.next
self.no -= 1
def remove_last(self):
if self.head is not None:
if self.head.next is None:
self.remove_first()
else:
ptr = self.head
pre = self.head
while ptr.next is not None:
pre = ptr
ptr = ptr.next
pre.next = None
self.current = pre
self.no -= 1
remove_first(): 맨 앞의 노드를 삭제하는 함수remove_last(): 맨 뒤의 노드를 삭제하는 함수- 리스트에 노드가 하나만 존재할 때와 2개 이상 존재할 때를 나누어서 처리
def remove(self, p: Node) -> None:
if self.head is not None:
if p is self.head:
self.remove_first()
else:
ptr = self.head
while ptr.next is not p:
ptr = ptr.next
if ptr is None:
return
ptr.next = p.next
self.current = ptr
self.no -= 1
def remove_current(self) -> None:
self.remove(self.current)
remove(): 특정 노드를 삭제하는 함수- 삭제한 후 찾은 이전 노드의 다음 노드를 주어진 노드
p의 다음 노드로 설정하여 노드p를 제거
- 삭제한 후 찾은 이전 노드의 다음 노드를 주어진 노드
remove_current(): 현재 노드를 제거하는 함수
해시 테이블 (Hash Table)
Key와Value를 저장하는 자료 구조- 해시 함수를 사용하여 키를 해시 값으로 변환한 후, 해당 해시 값의 인덱스에 해당하는 위치에 값을 저장
# 개방 주소법을 사용한 해시 테이블 구현
class Status(Enum):
OCCUPIED = 0 # 사용 중인 상태
EMPTY = 1 # 비어있는 상태
DELETED = 2 # 삭제된 상태
class Bucket:
def __init__(self, key: Any, value: Any = None, stat: Status = Status.EMPTY) -> None:
self.key = key
self.value = value
self.stat = stat
def set(self, key, value, stat: Status) -> None:
self.key = key
self.value = value
self.stat = stat
def set_stat(self, stat: Status) -> None:
self.stat = stat
Status: 버킷의 상태를 나타냄Bucket: 버킷은 해시 테이블의 각 슬롯에 해당
class OpenHash:
def __init__(self, capacity: int) -> None:
self.capacity = capacity
self.table = [Bucket()] * self.capacity
# 해시값을 계산하는 함수
def hash_value(self, key: Any) -> int:
if isinstance(key, int):
return key % self.capacity
return int(hashlib.md5(str(key).encode()).hexdigest(), 16) % self.capacity
# 재해시값을 구함
def rehash(self, key: Any) -> int:
return(self.hash_value(key) + 1) % self.capacity
__init__(): 해시 테이블의 크기를 초기화하고, 각 슬롯에는 기본적으로 빈 버킷을 생성hash_value(): 주어진 키의 해시 값을 계산하는 함수rehash(): 충돌이 발생했을 떄 재해시 값을 계산
# key인 버킷을 검색
def search_node(self, key: Any) -> Any:
hash = self.hash_value(key)
p = self.table[hash]
for i in range(self.capacity):
if p.stat == Status.EMPTY:
break
elif p.stat == Status.OCCUPIED and p.key == key:
return p
hash = self.rehash(hash)
p = self.table[hash]
return None
# key인 원소를 검색하여 값을 반환
def search(self, key: Any) -> Any:
p = self.search_node(key)
if p is not None:
return p.value
else:
return None
search_node(): 주어진 키를 갖는 버킷을 검색하는 함수search(): 주어진 키에 해당하는 값을 반환하는 함수
# 키가 key이고 값이 value인 원소를 추가
def add(self, key: Any, value: Any) -> bool:
if self.search(key) is not None:
return False
hash = self.hash_value(key)
p = self.table[hash]
for i in range(self.capacity):
if p.stat == Status.EMPTY or p.stat == Status.DELETED:
self.table[hash] = Bucket(key, value, Status.OCCUPIED)
return True
hash = self.rehash(hash)
p = self.table[hash]
return False
# 키가 key인 원소를 삭제
def remove(self, key: Any) -> int:
p = self.search_node(key)
if p is None:
return False
p.set_status(Status.DELETED)
return True
add(): 주어진 키와 값을 해시 테이블에 추가하는 함수. 이미 존재하는 키인 경우에는 추가하지 않는다remove(): 주어진 키에 해당하는 값을 삭제한다.
2. CS:APP (1.1 ~ 1.4)
컴파일 과정
- 전처리 (Preprocessing)
소스 코드에서 전처리 지시문을 처리 (ex.
#include,#define등) - 컴파일 (Compiler)
전처리된 소스 코드를 읽어들여 어셈블리 코드 생성 (+ 언어의 문법 검사, 메모리 할당)
- 어셈블리 (Assembly)
컴파일러에 의해 생성된 어셈블리 코드를 Object File로 변환
- 링크 (Linking)
여러 개의 객체 파일과 라이브러리 파일을 결합하여 하나의 실행 파일을 생성 (각 파일 간의 의존 관계 해결)
시스템의 하드웨어 조직
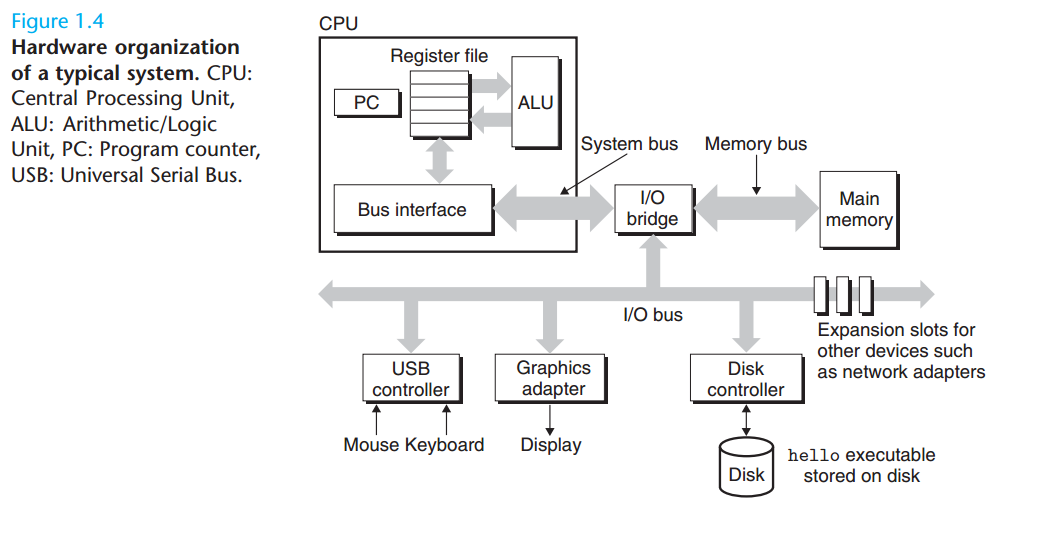
✔ 버스 (Bus)
- 컴퓨터 시스템 내에서 데이터, 주소 및 제어 신호를 전송하는 통로
- CPU와 메모리, 입출력 장치들 간의 통신을 담당
- 버스의 폭은 한 번에 전송할 수 있는 비트 수를 의미하며, 이는 시스템 데이터 전송 속도에 영향을 미침
✔ 입출력 장치 (Input/Output Devices)
- 컴퓨터와 외부 환경 간의 상호 작용 담당 (ex. 키보드, 마우스, 모니터, 프린터, 디스트 드라이브 등)
- 입력 장치는 사용자로부터 데이터를 받아들이고, 출력 장치는 컴퓨터에서 생성된 데이터를 표시하거나 출력
- 각각의 입출력 장치는 컴퓨터와 버스를 통해 통신하며, 이를 통해 데이터를 주고받고 제어 신호를 전송
✔ 메인 메모리 (Main Memory)
- 컴퓨터가 프로그램과 데이터를 저장하고 접근하는 데 사용되는 주 기억장치
- 주로 RAM으로 구성되며, 휘발성이므로 전원이 꺼지면 데이터가 손실
- 프로세서가 명령어와 데이터에 빠르게 접근할 수 있도록 함
- 주소 버스를 통해 주소 지정, 데이터 버스를 통해 데이터 전송, 제어 버스를 통해 메모리와 프로세서 간의 데이터 전송과 제어 신호가 이루어짐
✔ 프로세서 (Processor)
- 컴퓨터의 중앙 처리 장치, 프로그램의 명령어를 해석하고 실행하는 역할 (CPU)
- 시스템 버스를 통해 메인 메모리와 입출력 장치와 통신, 주소 버스를 통해 메모리의 주소 지정, 제어 버스를 통해 명령어 실행과 제어 신호 전송
- 인스트럭션의 요청에 의해 CPU가 실행하는 단순한 작업의 예: 적재 (Load), 저장 (Store), 작업 (Operate), 점프 (Jump)
